Python | Pandasの基礎 (“Series”, “DataFrame”, CSVファイルの利用)

Pythonとは,高レベルの汎用プログラミング言語であり,読みやすさとシンプルさで知られている.Web開発やデータサイエンス,人口知能,機械学習など幅広く利用されている.なお,レベルの高低はハードウェアに近いかどうかを意味しており,レベルが低いとハードウェアに近いことを意味している.
Pandasとは,Python向けに人気のあるオープンソースのデータ操作および分析ライブラリーである.異なるフォーマットでの読み書きするツールに加えて,効率的にデータ保存および大規模なデータセットを操作するためのデータ構造を提供する.
本記事では,Pandasの基礎の2つの"class"である一次元データを利用する"Series"と二次元データを利用する"DataFrame", そして"CSVファイルの読み込み・書き込み"を記す.
- Series
- DataFrame
- CSVファイルの読み込み・書き込み
pandas | User Guide | 10 minutes to pandas
実施環境
各バージョンの確認方法はこちら
OS: Windows11
VS Code: 1.85.1
Python 3.12.0
Pandas 2.1.4
Numpy 1.26.2
事前準備
Pandasを利用する際,必要であれば,以下コマンドを実行する.
$ pip install pandasSeries
“Series"とは,任意の一次元データを保持できるクラスである.Excelの列やデータベーステーブルの単一の列に似ている.
一次元データの出力
Pyファイルに以下を入力し,実行する.
import pandas as pd
# Creating a Series
s = pd.Series([1, 3, 5, 6, 8])
# Displaying the Series
print(s)■実行結果
0 1
1 3
2 5
3 6
4 8
dtype: int64NaNを含むデータの出力
Pyファイルに以下を入力し,実行する.
import pandas as pd
import numpy as np
# Creating a Series
s = pd.Series([1, 3, 5, np.nan, 6, 8])
# Displaying the Series
print(s)※上記コードにて,NaN(Not a Number: 非数)を表示するには,以下を実施し"np.npn"を利用する必要がある.0/0のように,計算結果が存在しない際にNaNが利用される.
import numpy as np■実行結果
0 1.0
1 3.0
2 5.0
3 NaN
4 6.0
5 8.0
dtype: float64データタイプ(“dtype")の出力
以下では,"s"にデータが格納されている.print(s.dtype)を実行することで"s"に格納されているデータのタイプを出力できる.
pandas | User Guide | Essential basic functionality | dtype
なお,"dtype"の詳細については,以下記事が参照になる.
shelokuma tech blog | python | pandasにおけるdtypeの詳細
Pyファイルに以下を入力し,実行する.
import pandas as pd
# Creating a Series
s = pd.Series([1, 3, 5, 6, 8])
# Checking the data type
print("dtype:", s.dtype)■実行結果
dtype: int64“data type"を特定させたデータの出力
Seriesの丸カッコ内に,データタイプ(今回は"dtype=’float64′")を以下のように特定させてデータを出力させることができる.
Pyファイルに以下を入力し,実行する.
import pandas as pd
# Creating a Series
s = pd.Series([1, 3, 5, 6, 8], dtype='float64')
# Displaying the Series
print(s)■実行結果
0 1.0
1 3.0
2 5.0
3 6.0
4 8.0
dtype: float64DataFrame
“DataFrame"とは,行と列を含む二次元データを保持するクラスである.これは,Pandasでは主要なデータ構造として利用されており,ExcelやSQLテーブルに類似している.
二次元データの出力
Pyファイルに以下を入力し,実行する.
import pandas as pd
# Creating a DataFrame from a dictionary
data = {'Name': ['John', 'Jane', 'Bob'],
'Age': [28, 24, 22],
'City': ['New York', 'San Francisco', 'Los Angeles']}
df = pd.DataFrame(data)
# Displaying the DataFrame
print(df)■実行結果
Name Age City
0 John 28 New York
1 Jane 24 San Francisco
2 Bob 22 Los Angeles特定の列の出力
“Name"列のラベルのデータを出力させるため,"print(df['Name’])"を実行する.
Pyファイルに以下を入力し,実行する.
import pandas as pd
# Creating a DataFrame from a dictionary
data = {'Name': ['John', 'Jane', 'Bob'],
'Age': [28, 24, 22],
'City': ['New York', 'San Francisco', 'Los Angeles']}
df = pd.DataFrame(data)
# Accessing a specific column
print(df['Name'])■実行結果
0 John
1 Jane
2 Bob
Name: Name, dtype: object特定条件のデータの出力(<, >, <=, >=)
特定の条件のデータを出力させるため,不等号を利用することで条件指定をすることができる.今回は,年齢が24歳以上のデータを出力する.
Pyファイルに以下を入力し,実行する.
import pandas as pd
# Creating a DataFrame from a dictionary
data = {'Name': ['John', 'Jane', 'Bob'],
'Age': [28, 24, 22],
'City': ['New York', 'San Francisco', 'Los Angeles']}
df = pd.DataFrame(data)
# Filtering rows based on a condition
filtered_df = df[df['Age'] >= 24]
print(filtered_df)■実行結果
Name Age City
0 John 28 New York
1 Jane 24 San Francisco列データの追加
dataに列データを追加することができる.
Pyファイルに以下を入力し,実行する.
import pandas as pd
# Creating a DataFrame from a dictionary
data = {'Name': ['John', 'Jane', 'Bob'],
'Age': [28, 24, 22],
'City': ['New York', 'San Francisco', 'Los Angeles']}
df = pd.DataFrame(data)
# Adding a new column
df['Salary'] = [50000, 60000, 45000]
print(df)■実行結果
Name Age City Salary
0 John 28 New York 50000
1 Jane 24 San Francisco 60000
2 Bob 22 Los Angeles 45000データがない場合のハンドリング
Dropnaの利用
data内の数字に"NaN"などがある場合,"dropna"を利用することで,当該行を削除することができる."Age"に"NaN(np.nan)"があるので,"Name": “Tom", “City": “Florida"が表示されない.
pandas | pandas.DataFrame.dropna
Pyファイルに以下を入力し,実行する.
import pandas as pd
import numpy as np
# Creating a DataFrame from a dictionary
data = {'Name': ['John', 'Jane', 'Bob', 'Tom'],
'Age': [28, 24, 22, np.nan],
'City': ['New York', 'San Francisco', 'Los Angeles', 'Florida']}
df = pd.DataFrame(data)
# Dropping rows with missing values
df = df.dropna()
# Displaying the DataFrame
print(df)■実行結果
Name Age City
0 John 28.0 New York
1 Jane 24.0 San Francisco
2 Bob 22.0 Los AngelesFillnaの利用
data内の数字に"NaN"などがある場合,"fillna"を利用することで,"NaN"を"0.0″に変換することができる."Age"に"NaN(np.nan)"があるので,"0.0″が表示される.
pandas | pandas.DataFrame.fillna
Pyファイルに以下を入力し,実行する.
import pandas as pd
import numpy as np
# Creating a DataFrame from a dictionary
data = {'Name': ['John', 'Jane', 'Bob', 'Tom'],
'Age': [28, 24, 22, np.nan],
'City': ['New York', 'San Francisco', 'Los Angeles', 'Florida']}
df = pd.DataFrame(data)
# Filling missing values with a specific value
df = df.fillna(0)
# Displaying the DataFrame
print(df)■実行結果
Name Age City
0 John 28.0 New York
1 Jane 24.0 San Francisco
2 Bob 22.0 Los Angeles
3 Tom 0.0 FloridaCSVファイルの読み込み・書き込み
CSVファイルの書き込み
dataの中身をCSVファイルに書き込み,出力することができる.
pandas | pandas.DataFrame.to_csv
Pyファイルに以下を入力し,実行する.
import pandas as pd
# Creating a DataFrame from a dictionary
data = {'Name': ['John', 'Jane', 'Bob'],
'Age': [28, 24, 22],
'City': ['New York', 'San Francisco', 'Los Angeles']}
df = pd.DataFrame(data)
# Writing to a CSV file
df.to_csv('output_filename.csv', index=False)■実行結果
以下のように,フォルダ内に"output_filename.csv"を出力することができた.
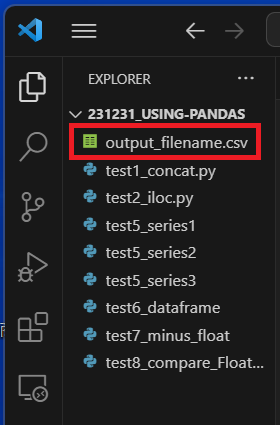
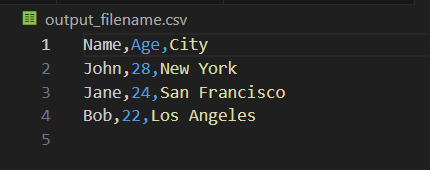
“output_filename.csv"にdataの中身を書き込むことができた.
CSVファイルの読み込み
CSVファイルの中身を読み込みすることができる.
フォルダ内に,以下のようにCSVファイルを作成する.
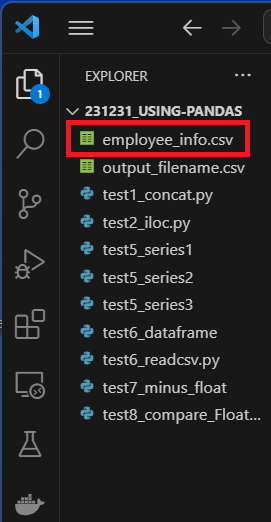
CSVファイルの中身を以下のように編集する.
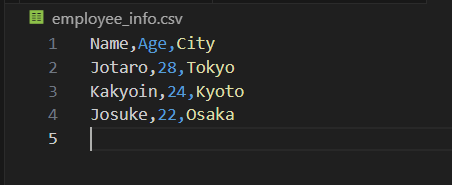
Pyファイルに以下を入力し,実行する.
import pandas as pd
# Reading a CSV file
df = pd.read_csv('employee_info.csv')
print(df)ターミナルに以下のように,CSVファイル内のデータが出力される.
Name Age City
0 Jotaro 28 Tokyo
1 Kakyoin 24 Kyoto
2 Josuke 22 Osaka参照
pandas | User Guide | 10 minutes to pandas
pandas | User Guide | Essential basic functionality | dtype
shelokuma tech blog | python | pandasにおけるdtypeの詳細
pandas | pandas.DataFrame.describe
pandas | pandas.DataFrame.dropna
pandas | pandas.DataFrame.fillna
pandas | pandas.DataFrame.to_csv
Medium | pandas for Data Science: Part1
以上